
软件介绍
NormCap 是一款基于本地大模型的 OCR文字识别工具,支持离线使用,确保数据安全。它能准确识别图片中的文字,适用于多种语言和平台,适合需要快速提取文本内容的用户。
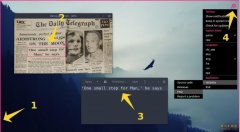
NormCap(OCR文字识别)
这款工具可以直接从屏幕截图中提取文字,而不是保存为图片格式。
主要功能
多语言支持
利用 Tesseract 的多语言模型,能识别不同语言的文字。
注重隐私保护
所有识别过程都在本地完成,不会上传任何数据。
智能解析
自动检测邮件地址和网址,方便直接使用。
多显示器适配
无论使用多少显示器或不同缩放比例,都能正常识别。
跨平台运行
兼容 Windows、macOS 和 Linux 系统。
免费开源
采用 GPLv3 协议,代码可在 GitHub 查看。
安装方法
第一步:在 macOS 上首次运行时,需前往“系统偏好设置”→“安全性与隐私”→“通用”,选择“仍要打开”。可能还需要授权截图权限。
第二步:由于是手动构建版本,启动时可能会有短暂延迟。
其他安装方式
Windows 用户可在 Microsoft Store 下载。
Arch/Manjaro 用户可通过 AUR 安装。
Linux 用户可使用 FlatHub 安装 Flatpak 版本。
0.5.4 版本更新
修复了重复启动时窗口重复出现的问题。
优化了 Linux 系统下 Wayland 的窗口定位稳定性。
改进了剪贴板相关操作的调试信息输出。
 问小白下载
问小白下载 思语下载
思语下载 Xterminal下载
Xterminal下载 Hex-Rays IDA下载
Hex-Rays IDA下载 wins解压缩下载
wins解压缩下载 Zbrush 2025下载
Zbrush 2025下载 Easy Image X2下载
Easy Image X2下载 Adobe Fresco
Adobe Fresco
 中望CAD Pro
中望CAD Pro
 SolidWorks 2024
SolidWorks 2024 B-Renderon
B-Renderon PhotoBoost
PhotoBoost PixPin
PixPin Nevercenter Silo 2024
Nevercenter Silo 2024
用户评论