

软件介绍
FasterWhisperGUI是一款基于fast_whisper开发的图形界面工具,专为音视频转录设计。它支持多种输出格式,并集成了多种AI模型,适合需要高效处理语音转文字任务的用户。
FasterWhisperGUI功能详解
这款软件采用PySide6框架开发,能够将音频或视频内容转换成srt、txt、smi等多种字幕格式。它不仅能转换OpenAI-whisper模型为ct2格式,还提供了VAD模型和完整的whisper参数设置,兼容whisperX、Demucs以及最新的whisper large-v3模型。
提到Whisper,很多人应该不陌生。这是OpenAI开发的语音识别模型,能实现本地实时语音转文字,常用于翻译和字幕制作。之前介绍过的Constme-Whisper虽然也能离线识别语音并支持GPU加速,但这款新工具功能更全面。
faster-whisper-GUI在原有基础上增加了更多实用功能,可以轻松将音视频转换为多种字幕格式。它整合了Demucs、FastWhiper、whisperX和VAD-model等技术,可调节的参数选项也比同类工具更丰富。
需要注意的是,这类离线处理工具通常体积较大。软件安装包就有1.6GB,安装后占用空间超过6GB,这还不包括后续添加的模型文件。建议安装在剩余空间较大的磁盘分区。

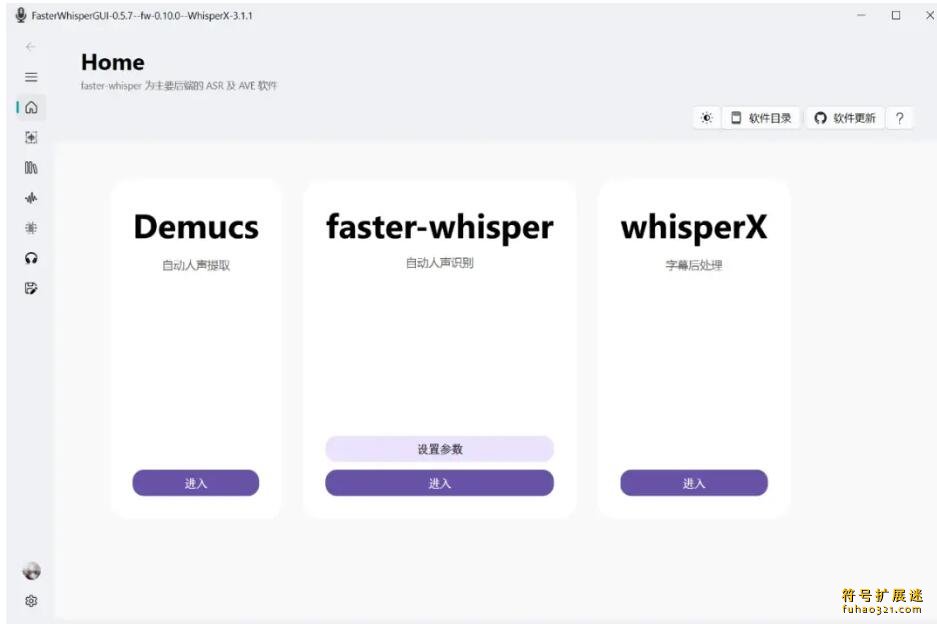
处理音频分离任务时,直接把文件拖入窗口即可。测试效果令人满意,还能单独设置输出内容。
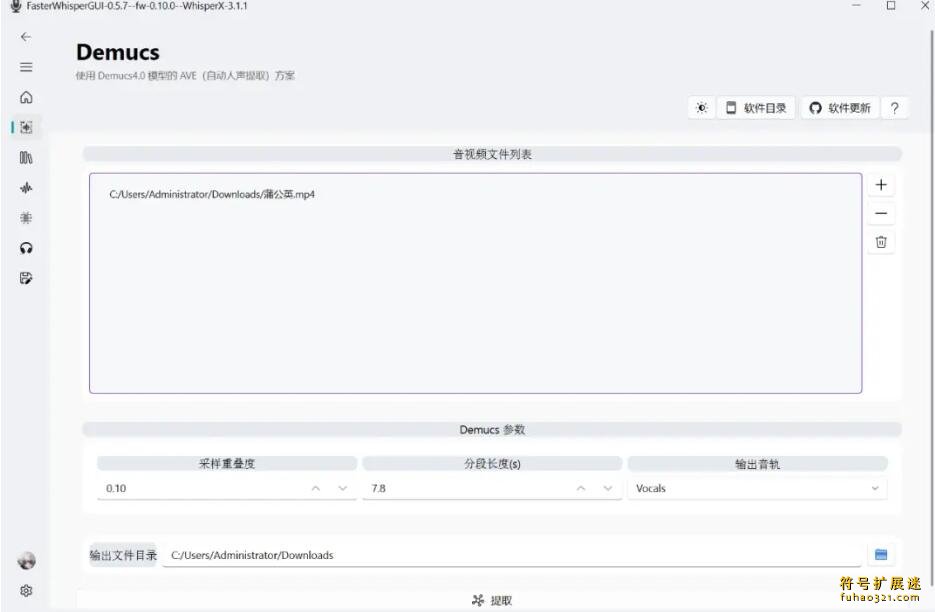

使用额外模型时要注意选择处理设备。如果不是NVIDIA显卡,建议选择自动模式,否则可能导致加载失败。
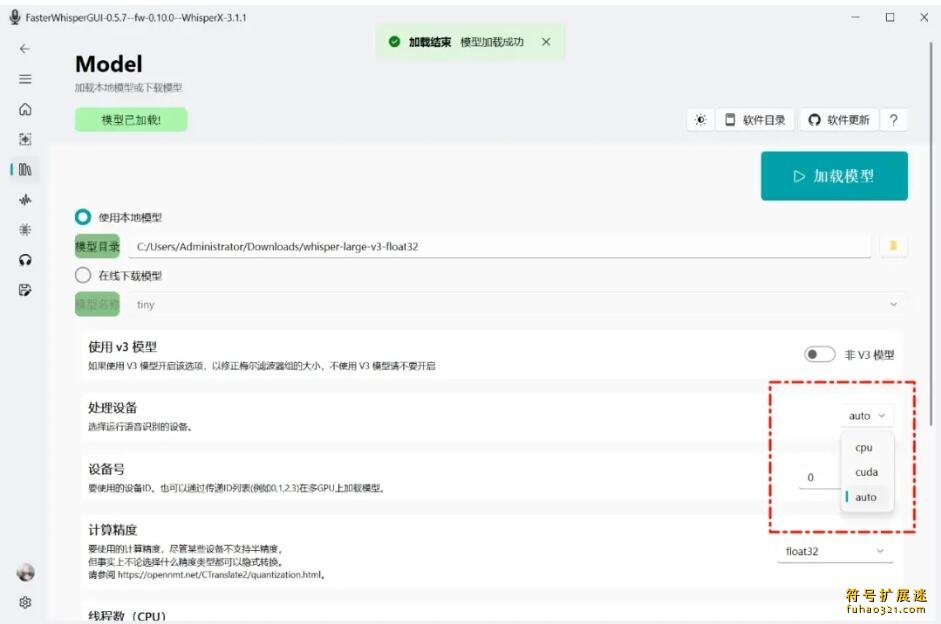
软件提供多种模型可选,使用带V3标志的模型时需要手动开启对应选项。

V3模型需要特别注意开启相应开关。
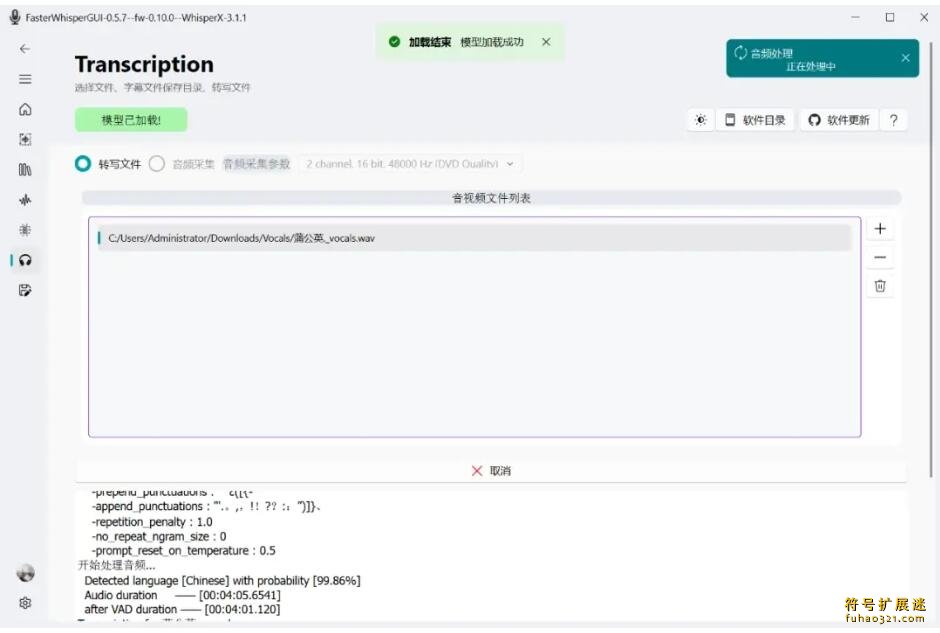

语音转文字功能支持后台运行,处理时间较长时可以切换到其他界面。识别结果准确度较高,能正确处理中英文混排和大小写等细节。
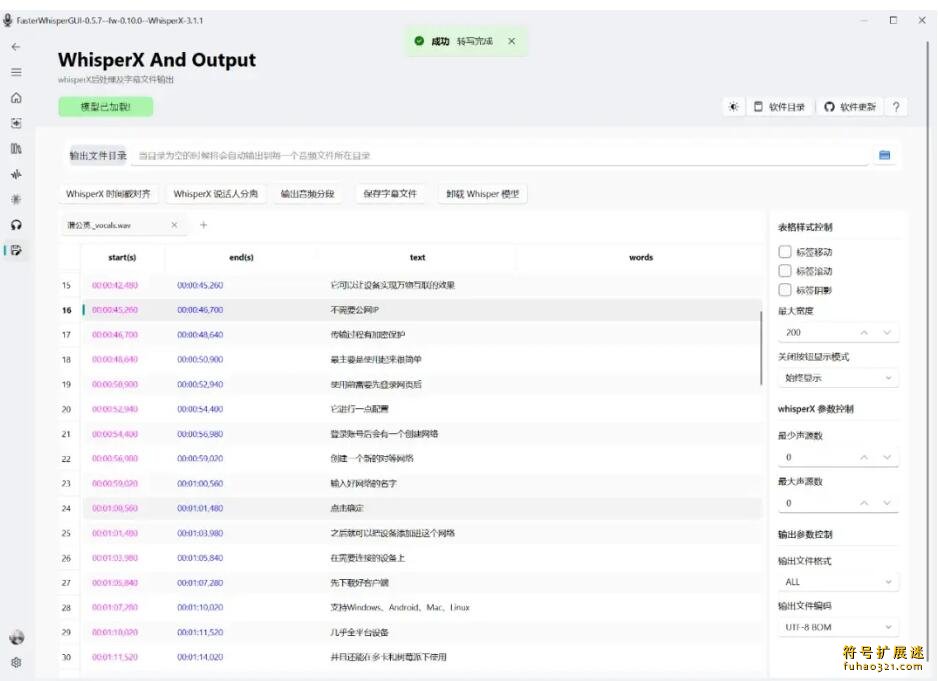
和人工识别一样,机器转写也会存在少量错误。软件会自动跳转到字幕编辑界面,方便快速修正错误、分割不同说话人的内容。

设置选项相当丰富,可以调整默认语言、翻译参数,还能设置防止幻听的各种阈值。
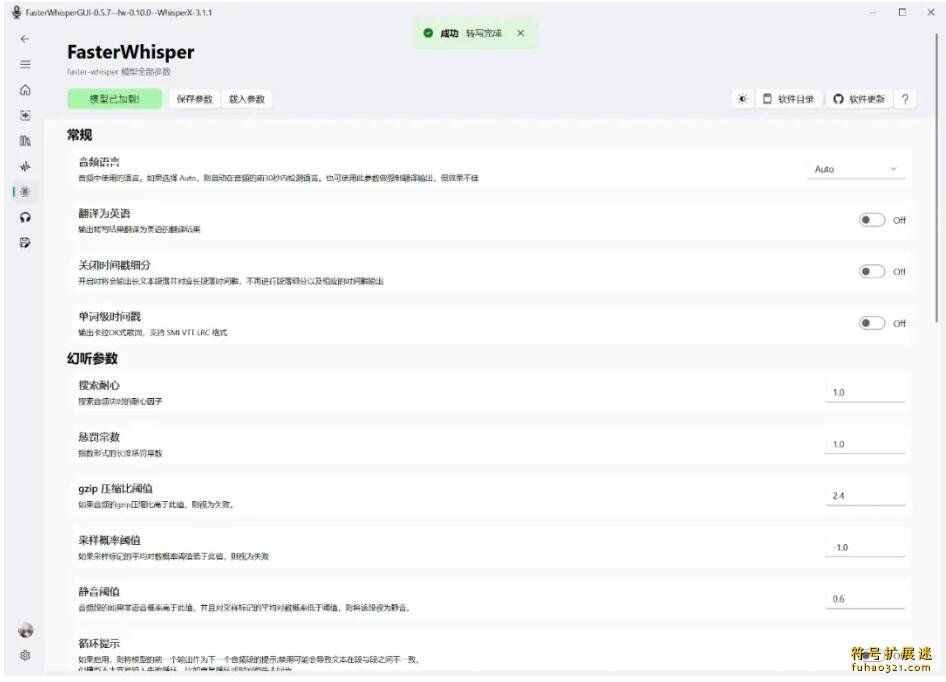
类似功能在其他视频编辑软件中通常需要付费或依赖云端服务,识别效果也不见得更好。
版本更新记录
0.8.0版本主要更新内容:
修复了赞助渠道缺失的问题 #126
将faster-whisper升级至1.02版
新增对distil-large-v3模型在线模式的支持 #130
Distil-Whisper模型distil-large-v3专为配合OpenAI顺序算法设计
支持初始化更多whisper模型参数
音频处理设置
max_new_tokens: 限制每个区块生成的新令牌数量,未设置时使用默认max_size值
chunk_length: 自定义音频段长度,会覆盖FeatureExtractor的默认chunk_size
clip_timestamps: 设置需要处理的音频时间段,格式为"开始,结束,开始,结束..."
幻听抑制参数
hallucination_silence_threshold: 启用word_timestamps时,跳过超过该阈值的静音段
其他配置
hotwords: 输入提示词来引导模型,如"the video is about comfyUI"
常规设置
language_detection_threshold: 语言标记概率超过该值时判定为检测到语言
language_detection_segments: 语言检测需要分析的分段数量
更多新特性详见:https://github.com/SYSTRAN/faster-whisper/releases/tag/v1.0.2
修复了字幕复制功能的bug
优化了部分界面文字
暂时禁用了转写参数页面的参数保存/读取功能
调整了起止时间和说话人列的显示位置
升级pytorch至2.3.0版本,支持CUDA12
使用注意事项
安装新版本前需完全卸载旧版(可保留cache文件夹)
需要预先安装ffmpeg
使用V3模型时若出现显存溢出,建议更新显卡驱动或回退到稳定版本
 GibbsCAM下载
GibbsCAM下载 GhostVolt Business下载
GhostVolt Business下载 TShell下载
TShell下载 LibreWolf下载
LibreWolf下载 闪电藤下载
闪电藤下载 Opal下载
Opal下载 图片无损放大工具下载
图片无损放大工具下载 Adobe Fresco
Adobe Fresco 中望CAD Pro
中望CAD Pro
 SolidWorks 2024
SolidWorks 2024 B-Renderon
B-Renderon PhotoBoost
PhotoBoost
 PixPin
PixPin Nevercenter Silo 2024
Nevercenter Silo 2024
用户评论