

软件介绍
CosyVoice是一款基于大模型技术的语音合成工具,专注于自然语音生成和多语言支持。它通过深度学习技术实现文本到语音的实时转换,适用于智能设备、音视频创作等多种场景。与传统语音生成技术相比,CosyVoice在音色逼真度和情感控制上表现更出色。
CosyVoice的核心功能
这款工具能够将文本转化为流畅的语音,支持多种应用场景。比如,它可以为智能客服、智能音箱、数字人等设备提供语音播报功能。同时,它也适用于小说阅读、新闻播报、影视解说等音视频创作领域。
多语言与音色控制
CosyVoice支持中英日粤韩五种语言的语音生成,效果远超传统模型。只需3到10秒的原始音频,它就能模拟出音色,甚至还原韵律和情感细节。它还允许通过富文本或自然语言对生成语音的情感和韵律进行精细调整。
技术优势
CosyVoice采用语音量化编码技术,将语音离散化处理,依托大模型实现自然流畅的生成效果。研究团队提供了多种模型版本,包括基模型CosyVoice-300M、微调模型CosyVoice-300M-SFT以及支持细粒度控制的CosyVoice-300M-Instruct,满足不同场景需求。
性能对比
与ChatTTS等工具相比,CosyVoice在内容一致性和语义建模上表现更优,几乎没有额外多字的现象。通过对合成音频的重打分,它的识别错误率更低,甚至在说话人相似度上超越了人类发音水平。
使用说明
第1步:选择推理模式。
第2步:点击骰子按钮(可选),调整说话人的语调和韵律。
第3步:按照提示完成操作。
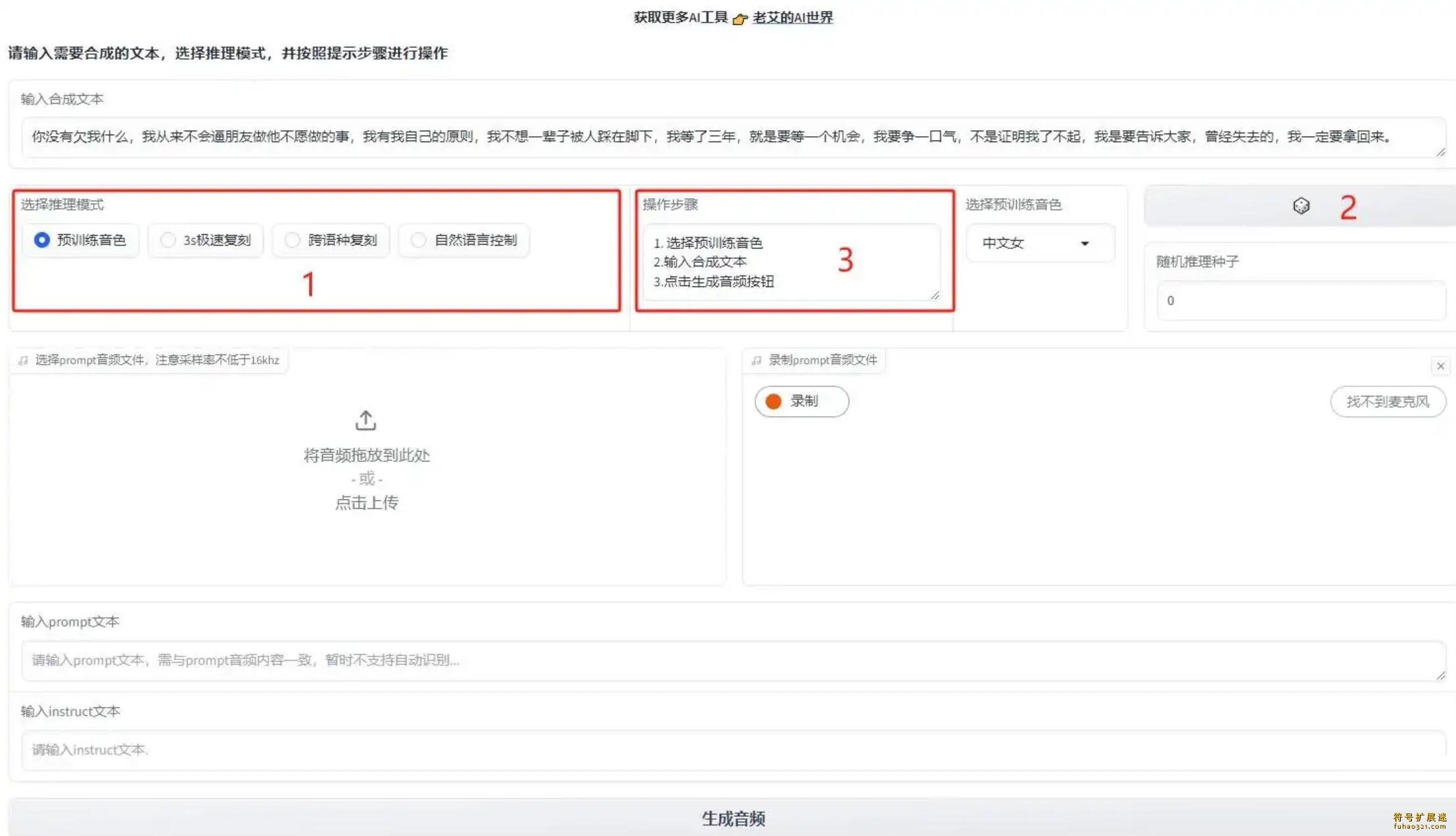
稍等片刻,程序处理完成后,可以在输出音频界面播放或下载生成的语音。
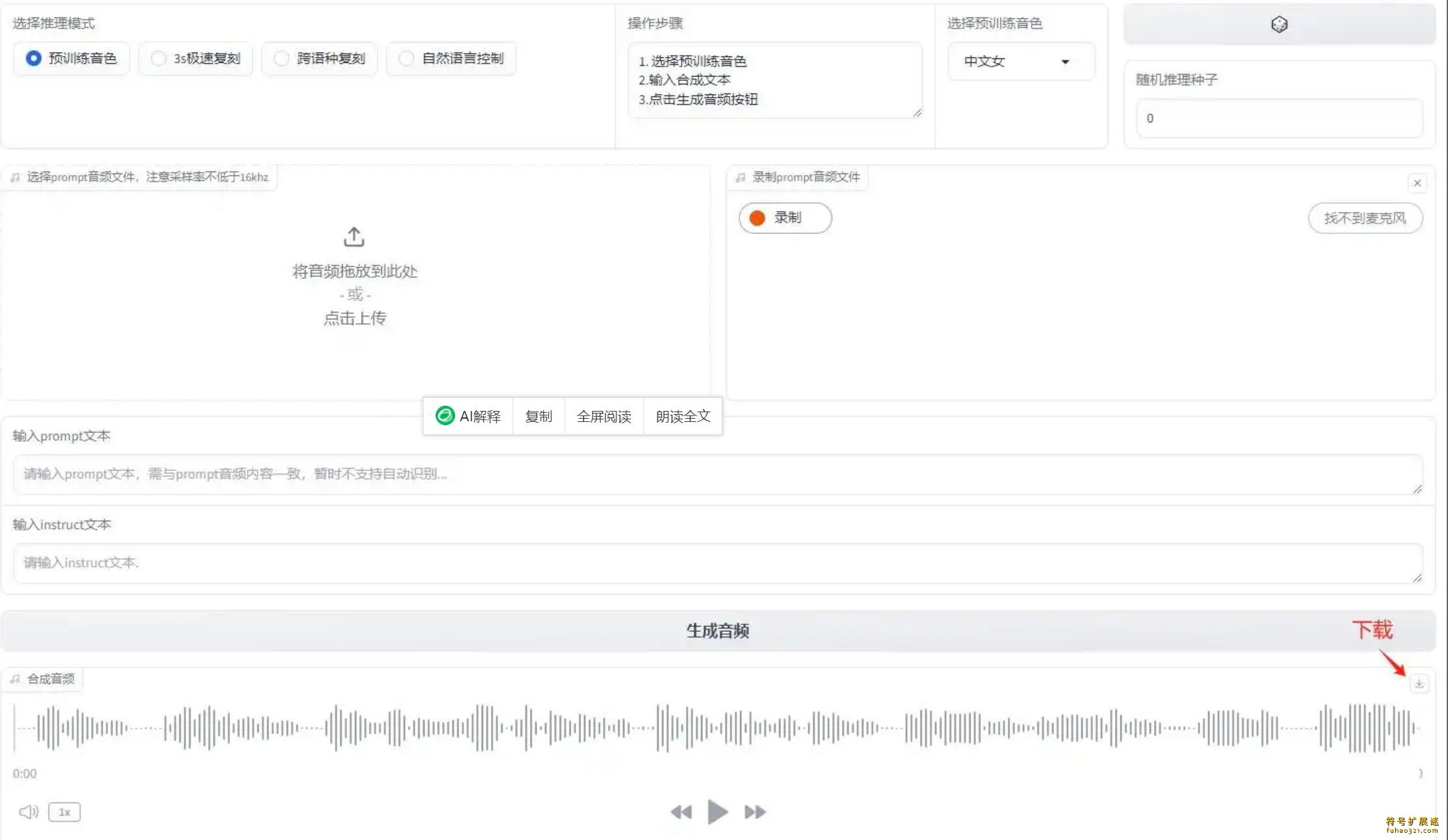
注意事项
① 安装路径中不要包含中文。
② 建议使用GTX1060及以上显卡运行。
③ 如果软件后台意外关闭,请重新打开并刷新网页。
更新内容
手动选择参考音频
第1步:将需要克隆的参考音频复制到软件根目录下的“参考音频”文件夹,并将文件名改为音频内容。
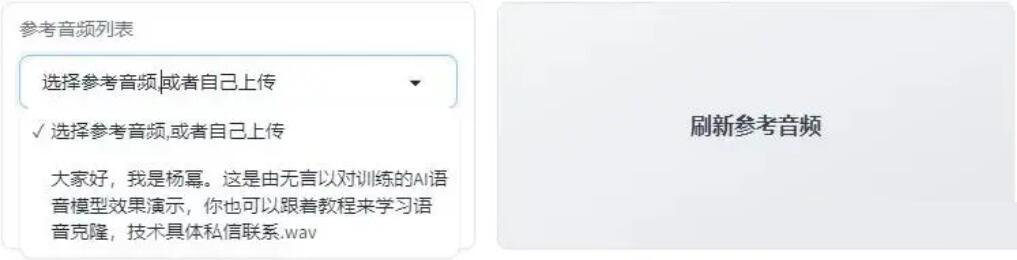

第2步:点击“刷新参考音频”按钮即可完成操作。
自定义音色保存
第1步:生成克隆音色后,在下方输入音色名称并保存。

例如,将克隆后的音色命名为“大幂幂”。
第2步:保存后,点击“刷新新增音色”按钮。
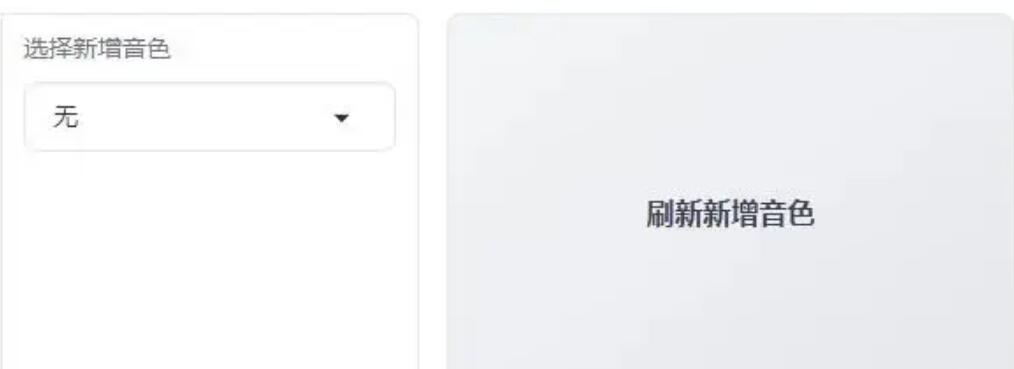
第3步:在新增音色列表中找到“大幂幂”音色。
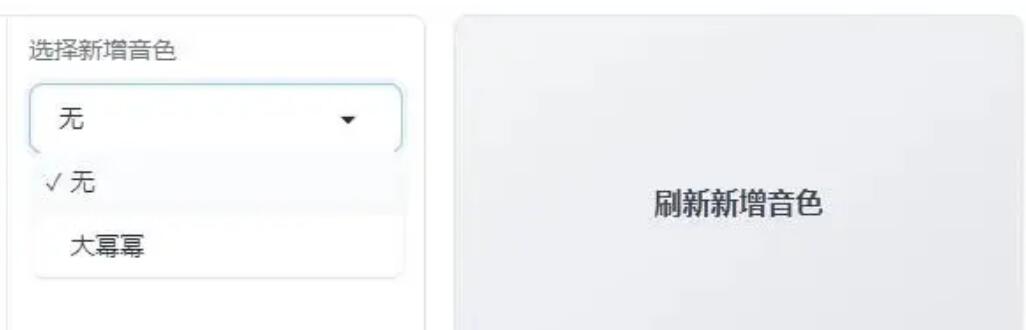
之后需要生成音频时,直接选择“大幂幂”音色即可。
 keyviz下载
keyviz下载 Cherry Studio下载
Cherry Studio下载 QLiteStudio下载
QLiteStudio下载 Continue下载
Continue下载 KeePassXC下载
KeePassXC下载 Adobe Speech to Text for Pr下载
Adobe Speech to Text for Pr下载 讯飞星火下载
讯飞星火下载 Adobe Fresco
Adobe Fresco
 中望CAD Pro
中望CAD Pro
 SolidWorks 2024
SolidWorks 2024 B-Renderon
B-Renderon PhotoBoost
PhotoBoost PixPin
PixPin Nevercenter Silo 2024
Nevercenter Silo 2024
用户评论